سفری به قلب دگم مرکزی زیستشناسی و رمزگشایی از جریان اطلاعات حیات
بخش ۱: Central Dogma: طرح اولیه اطلاعات حیات
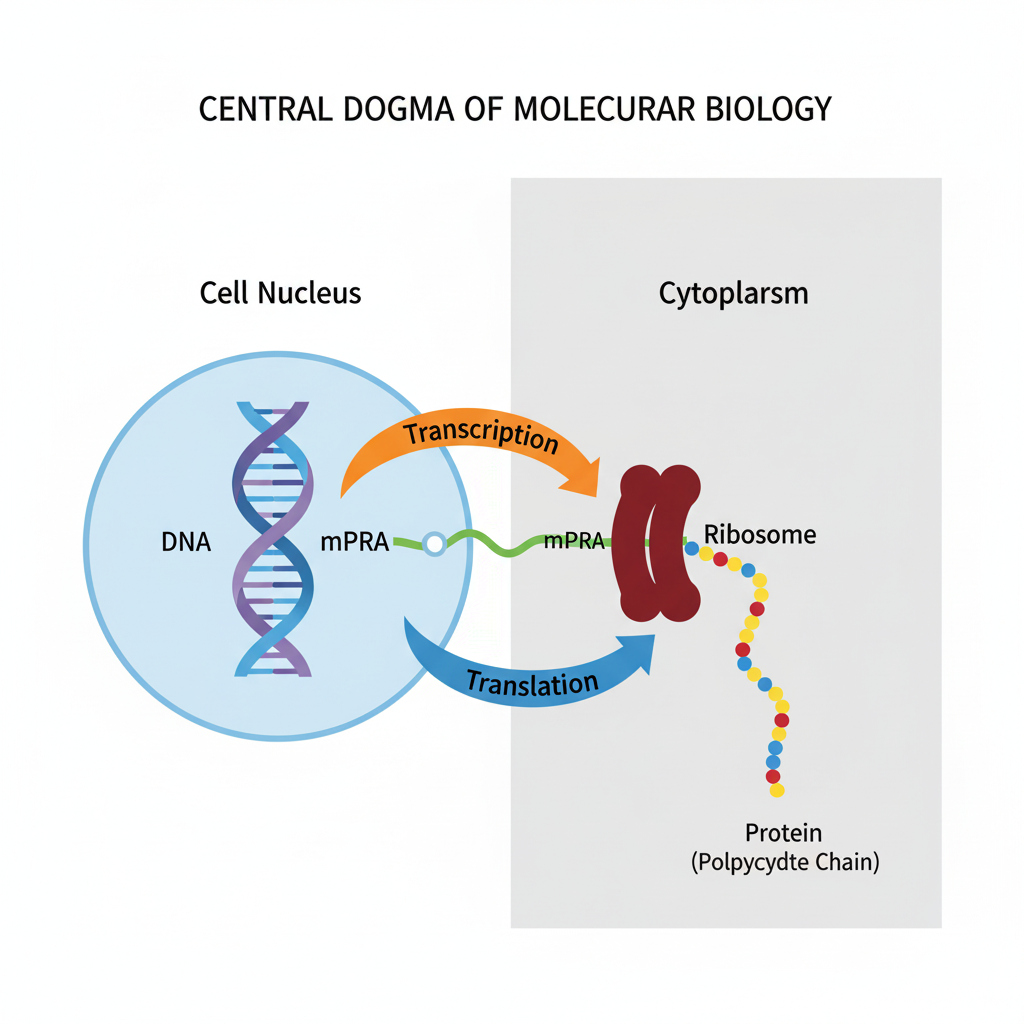
در قلب زیستشناسی مولکولی، یک اصل بنیادین قرار دارد که جریان اطلاعات ژنتیکی را در تمام اشکال حیات شناختهشده، از سادهترین باکتریها تا پیچیدهترین موجودات، توصیف میکند. این اصل که به عنوان «Central Dogma» شناخته میشود، چارچوبی را برای درک چگونگی تبدیل دستورالعملهای ذخیره شده در DNA به ماشینآلات عملکردی سلول، یعنی پروتئینها، فراهم میکند. این فرآیند، یک داستان شگفتانگیز از انتقال اطلاعات در مقیاس مولکولی است که در دو پرده اصلی، رونویسی و ترجمه، به اجرا در میآید.
۱.۱. تعریف جریان اطلاعات ژنتیکی: DNA → RNA → پروتئین
در سادهترین بیان، Central Dogma جریان یکطرفه اطلاعات را به این صورت توصیف میکند: اطلاعات ژنتیکی به صورت دائمی در مولکولهای دیاکسیرایبونوکلئیک اسید (DNA) ذخیره میشود. سپس، این اطلاعات در فرآیندی به نام رونویسی (Transcription) به یک مولکول پیامرسان موقتی به نام رایبونوکلئیک اسید پیامرسان (mRNA) کپی میشود. در نهایت، این پیام RNA در فرآیندی به نام ترجمه (Translation) توسط ساختارهایی به نام ریبوزومها خوانده شده و به یک زنجیره از اسیدهای آمینه، یعنی یک پروتئین، تبدیل میشود.1
- DNA (دیاکسیرایبونوکلئیک اسید): این مولکول دو رشتهای و پایدار، آرشیو اصلی و بلندمدت اطلاعات ژنتیکی سلول است. توالی بازهای نوکلئوتیدی آن (آدنین (A)، گوانین (G)، سیتوزین (C) و تیمین (T)) دستورالعملهای ساخت تمام پروتئینهای مورد نیاز یک موجود زنده را در خود جای داده است.
- RNA (رایبونوکلئیک اسید): این مولکول عمدتاً تکرشتهای، به عنوان یک واسطه چندمنظوره و کوتاهمدت عمل میکند. mRNA پیام را از DNA به کارخانه پروتئینسازی سلول منتقل میکند. انواع دیگر RNA، مانند RNA ریبوزومی (rRNA) و RNA ناقل (tRNA)، نیز نقشهای حیاتی در این فرآیند ایفا میکنند.
- پروتئین: این مولکولها، کارگران اصلی سلول هستند و وظایف بیشماری از جمله کاتالیز واکنشهای بیوشیمیایی (آنزیمها)، ایجاد ساختار (مانند کلاژن)، انتقال سیگنالها (گیرندهها) و تنظیم بیان ژن را بر عهده دارند.
مفهوم «اطلاعات» در این زمینه، معنای بسیار دقیقی دارد: «تعیین دقیق توالی»، چه توالی بازها در اسید نوکلئیک و چه توالی اسیدهای آمینه در پروتئین.5 بنابراین، Central Dogma بر انتقال وفادارانه اطلاعات توالی از یک نوع مولکول به نوع دیگر تأکید دارد.
۱.۲. زمینه تاریخی: دگم کریک و ظرافتهای آن
Central Dogma برای اولین بار در سال ۱۹۵۸ توسط فرانسیس کریک، یکی از کاشفان ساختار مارپیچ دوگانه DNA، مطرح شد.5 در آن زمان، دنیای زیستشناسی در تب و تاب درک چگونگی استفاده از اطلاعات نهفته در DNA بود. در این میان، تمایز قائل شدن بین فرمولبندی اولیه و دقیق کریک و نسخه سادهشدهای که بعدها توسط جیمز واتسون رایج شد، بسیار حائز اهمیت است.
دگم کریک (۱۹۵۸، بازبینی در ۱۹۷۰): اصل بنیادین در بیانیه کریک، یک ادعای منفی و بسیار قدرتمند بود: اطلاعات نمیتواند از پروتئین به پروتئین دیگر یا از پروتئین به اسید نوکلئیک بازگردد.5 این بیانیه، انتقال اطلاعات توالی از حوزه پروتئینها به بیرون را غیرممکن میدانست. نکته قابل تامل در فرمولبندی اولیه کریک، قدرت علمی نهفته در بیانیه منفی آن است. برخلاف مسیر سادهانگارانه «DNA → RNA → پروتئین» که صرفاً یک فرآیند رایج را توصیف میکند، بیانیه کریک یک فرضیه بسیار قدرتمند و قابل ابطال را مطرح کرد. این چارچوب دقیق علمی به این معناست که تنها یک مثال نقض مستند برای رد کردن این اصل کافی است. این اصل، با وجود اکتشافات بعدی، تا حد زیادی اعتبار خود را حفظ کرده است.
مسیر واتسون (۱۹۶۵): مسیر آشناتر «DNA → RNA → پروتئین» که توسط جیمز واتسون در کتاب «زیستشناسی مولکولی ژن» معرفی شد، یک توصیف مثبت و دو مرحلهای از رایجترین جریان اطلاعات است.3 اگرچه این مدل یک ابزار آموزشی عالی است، اما دقت کمتری نسبت به فرمولبندی کریک دارد و تمام فرآیندهای بیولوژیکی شناختهشده را پوشش نمیدهد.
استفاده کریک از واژه «دگم» نیز اغلب به اشتباه تفسیر شده است. او این واژه را نه به معنای یک اصل جزمی و اثباتناپذیر، بلکه برای توصیف یک فرضیه محوری به کار برد که در آن زمان شواهد مستقیم کمی برای آن وجود داشت، اما برای پایهریزی رشته نوپای زیستشناسی مولکولی ضروری بود.
۱.۳. دگم مدرن و گسترشیافته: استثناهایی که قاعده را روشن میکنند
از دهه ۱۹۷۰ به بعد، اکتشافات جدید مسیرهای دیگری از انتقال اطلاعات را آشکار ساختند که منجر به شکلگیری یک دیدگاه «گسترشیافته» از Central Dogma شد.2 این «استثناها» در واقع قاعده اصلی کریک را نقض نمیکردند، بلکه پیچیدگی و غنای دنیای بیولوژیکی را بیشتر به نمایش میگذاشتند.
- رونویسی معکوس (RNA → DNA): کشف آنزیم «رونویسبردار معکوس» (Reverse Transcriptase) در رتروویروسهایی مانند HIV و همچنین در فرآیندهای سلولی یوکاریوتی مانند سنتز تلومرها، نشان داد که اطلاعات میتواند در جهت معکوس، از RNA به DNA، جریان یابد. این کشف، اصل بنیادین کریک را نقض نکرد، زیرا جریان اطلاعات همچنان بین اسیدهای نوکلئیک باقی میماند، اما یک مسیر انتقال «ویژه» و جدید را به مدل اضافه کرد.2
- همانندسازی RNA (RNA → RNA): بسیاری از ویروسها که ژنوم آنها از RNA تشکیل شده است (مانند ویروس آنفولانزا و کرونا)، با استفاده از یک آنزیم «RNA پلیمراز وابسته به RNA»، از روی الگوی RNA خود نسخههای RNA جدید میسازند. این نیز یک مسیر انتقال ویژه دیگر است که در مدل ساده اولیه وجود نداشت.2
این «استثناها» صرفاً موارد نادر بیولوژیکی نیستند، بلکه در پدیدههای مهمی مانند بیماریهای ویروسی، سرطان و پیری نقش محوری دارند. رونویسی معکوس مکانیسم عملکرد رتروویروسها و همچنین عامل حفظ انتهای کروموزومهای ما (تلومرها) است که اختلال در آن با پیری و سرطان مرتبط است. همانندسازی RNA استراتژی حیاتی بسیاری از ویروسهای بیماریزا است. بنابراین، درک دگم گسترشیافته برای پزشکی و زیستشناسی مدرن امری حیاتی است.
پریونها: چالشی برای دگم؟ مورد پریونها، پروتئینهای عفونی که بدون نیاز به هیچ واسطه اسید نوکلئیکی، با القای تغییرات ساختاری در پروتئینهای سالم مشابه خود تکثیر میشوند، یک چالش جدی برای این ادعای دگم است که اطلاعات نمیتواند از پروتئین به پروتئین منتقل شود. با این حال، باید توجه داشت که پریونها اطلاعات ساختاری (نحوه تاخوردگی) را منتقل میکنند، نه اطلاعات توالی اسیدهای آمینه. این تمایز ظریف، بیانیه اصلی کریک را در چارچوب معنایی مورد نظر او، تا حد زیادی معتبر نگه میدارد.5
بخش ۲: رونویسی: نوشتن پیام
رونویسی اولین مرحله از بیان ژن است؛ فرآیندی ظریف و بسیار تنظیمشده که در آن، دستورالعملهای ژنتیکی ذخیرهشده در یک قطعه از DNA به یک مولکول RNA مکمل کپی میشود. این مولکول RNA که به آن «رونوشت» (Transcript) میگویند، به عنوان یک پیام موقتی عمل کرده و اطلاعات را از هسته سلول (در یوکاریوتها) به سیتوپلاسم، محل سنتز پروتئین، منتقل میکند. در این بخش، به بررسی دقیق ماشینآلات و مراحل این فرآیند، به ویژه در سلولهای یوکاریوتی، میپردازیم.
۲.۱. ماشینآلات رونویسی: RNA پلیمراز و فاکتورهای تنظیمی
بازیگر اصلی در صحنه رونویسی، آنزیم RNA پلیمراز است. این آنزیم پیچیده در طول یک رشته از DNA حرکت کرده و با خواندن توالی بازهای آن، نوکلئوتیدهای RNA مکمل را به یکدیگر متصل میکند تا یک رشته RNA جدید بسازد.8
یکی از تفاوتهای کلیدی بین پروکاریوتها و یوکاریوتها در همین ماشینآلات رونویسی نهفته است. در حالی که پروکاریوتها (مانند باکتریها) تنها یک نوع RNA پلیمراز برای سنتز تمام انواع RNA دارند، سلولهای یوکاریوتی از سه نوع متمایز RNA پلیمراز استفاده میکنند که هر یک وظیفه تخصصی خود را دارند. این تخصصگرایی، نشاندهنده پیچیدگی بسیار بیشتر تنظیم بیان ژن در یوکاریوتها است 10:
- RNA پلیمراز I: در ناحیهای از هسته به نام «هستک» (Nucleolus) قرار دارد و مسئول رونویسی ژنهای مربوط به RNAهای ریبوزومی (rRNA) است که اجزای ساختاری ریبوزومها را تشکیل میده دهند.
- RNA پلیمراز II: این آنزیم، تمرکز اصلی بحث ما خواهد بود، زیرا مسئول سنتز تمام RNAهای پیامرسان پیشساز (pre-mRNA) است که پروتئینها را کد میکنند.
- RNA پلیمراز III: این آنزیم، ژنهای مربوط به RNAهای ناقل (tRNA)، rRNA 5S و دیگر RNAهای کوچک را رونویسی میکند.
در یوکاریوتها، RNA پلیمراز II به تنهایی قادر به شناسایی و اتصال به DNA و آغاز رونویسی نیست. این آنزیم برای شروع کار خود به مجموعهای از پروتئینهای کمکی به نام فاکتورهای رونویسی عمومی (General Transcription Factors) نیاز دارد. این فاکتورها (مانند TFIID، TFIIB و غیره) ابتدا به ناحیه خاصی از DNA به نام «پروموتر» متصل شده و یک کمپلکس پیشآغازی (Preinitiation Complex – PIC) را تشکیل میدهند که سپس RNA پلیمراز II را به محل صحیح فرا میخواند.8 این کمپلکس پیشآغازی را میتوان به یک کامپیوتر مولکولی تشبیه کرد. این ساختار صرفاً یک سکوی فرود برای پلیمراز نیست، بلکه یک مرکز پردازش اطلاعات است که سیگنالهای متعددی (از توالیهای افزاینده، خاموشکننده و نشانههای تکاملی) را دریافت و یکپارچه میکند تا تصمیم بگیرد که آیا یک ژن باید رونویسی شود و با چه شدتی. این پیچیدگی، بازتابی از نیاز به تنظیم دقیق بیان ژن در موجودات پرسلولی است.
۲.۲. فرآیند رونویسی: یک نمایش سهپردهای
فرآیند رونویسی را میتوان به سه مرحله اصلی تقسیم کرد: آغاز، طویل شدن و پایان.
۲.۲.۱. آغاز (Initiation): یافتن خط شروع
رونویسی از یک توالی خاص DNA به نام پروموتر (Promoter) آغاز میشود که در بالادست (Upstream) ژن قرار گرفته و به عنوان سیگنال شروع عمل میکند.8 در بسیاری از ژنهای یوکاریوتی که توسط RNA پلیمراز II رونویسی میشوند، پروموتر حاوی یک توالی کلیدی به نام جعبه تاتا (TATA box) است. این توالی که غنی از بازهای آدنین (A) و تیمین (T) است، حدود ۲۵ تا ۳۰ جفتباز قبل از نقطه شروع رونویسی قرار دارد.8
فرآیند آغاز به صورت مرحلهای رخ میدهد:
- یکی از فاکتورهای رونویسی عمومی به نام TFIID (که خود شامل پروتئین متصلشونده به تاتا یا TBP است) جعبه تاتا را شناسایی کرده و به آن متصل میشود.13
- این اتصال، فراخوانی زنجیرهای از سایر فاکتورهای رونویسی عمومی و در نهایت RNA پلیمراز II را به پروموتر آغاز میکند.
- با کمک انرژی حاصل از هیدرولیز ATP، دو رشته DNA در ناحیه پروموتر از هم باز میشوند و یک ساختار حبابمانند به نام حباب رونویسی (Transcription Bubble) ایجاد میکنند. این حباب، رشته الگو را برای خوانده شدن توسط پلیمراز در دسترس قرار میدهد.8
۲.۲.۲. طویل شدن (Elongation): سنتز رونوشت RNA
پس از استقرار موفقیتآمیز پلیمراز، مرحله طویل شدن آغاز میشود. در این مرحله، رشته RNA به تدریج بلندتر میشود.
- RNA پلیمراز II در طول رشته الگو (Template Strand) ی DNA در جهت ‘۳ به ‘۵ حرکت میکند.8
- برای هر نوکلئوتید در رشته الگو، پلیمراز یک نوکلئوتید RNA مکمل را به انتهای ‘۳ رشته در حال رشد RNA اضافه میکند. این بدین معناست که رشته RNA در جهت ‘۵ به ‘۳ سنتز میشود.17
- رشته RNA حاصل، تقریباً با رشته دیگر DNA، یعنی رشته کدکننده (Coding Strand)، یکسان است، با این تفاوت مهم که در RNA، باز اوراسیل (U) جایگزین تیمین (T) میشود.8
۲.۲.۳. پایان (Termination): رسیدن به انتهای ژن
RNA پلیمراز تا زمانی که به سیگنال توقف برسد، به رونویسی ادامه میدهد. در یوکاریوتها، فرآیند پایان پیچیدهتر از پروکاریوتها است و با پردازش RNA ارتباط تنگاتنگی دارد.
- پلیمراز به رونویسی خود ادامه میدهد تا از یک توالی خاص به نام سیگنال پلیآدنیلاسیون (Polyadenylation Signal) (معمولاً AAUAAA در رونوشت RNA) عبور کند.8
- این سیگنال توسط مجموعهای از پروتئینها شناسایی میشود. این پروتئینها رونوشت RNA را در نقطهای مشخص، در پاییندست سیگنال، از پلیمراز در حال حرکت جدا میکنند.8
- این برش، مولکول pre-mRNA را آزاد میکند. RNA پلیمراز II ممکن است برای چند صد یا هزار نوکلئوتید دیگر به رونویسی ادامه دهد، اما رونوشت اضافی به سرعت تخریب شده و در نهایت پلیمراز از DNA جدا میشود.
۲.۳. پردازش پس از رونویسی در یوکاریوتها: بالغ کردن پیام
در سلولهای یوکاریوتی، رونوشتی که مستقیماً از DNA ساخته میشود (pre-mRNA)، هنوز برای ترجمه آماده نیست. این مولکول ناپایدار و ناقص باید در داخل هسته تحت یک سری تغییرات شیمیایی به نام پردازش پس از رونویسی (Post-transcriptional Processing) قرار گیرد تا به یک مولکول mRNA بالغ، پایدار و آماده برای صادرات به سیتوپلاسم تبدیل شود.6 این فرآیندها نه تنها مراحل مجزایی پس از رونویسی نیستند، بلکه به شکلی تنگاتنگ از نظر فیزیکی و عملکردی با خود فرآیند رونویسی جفت شدهاند. آنزیمهای پردازش به دم C-ترمینال (CTD) RNA پلیمراز II متصل میشوند و همزمان با ساخته شدن pre-mRNA، تغییرات لازم را اعمال میکنند. این جفتشدگی یک «کارخانه تولید mRNA» کارآمد را ایجاد میکند که در آن رونویسی، پردازش و خاتمه به صورت یک زنجیره پیوسته و تحت نظارت دقیق انجام میشوند، که این امر هم سرعت را افزایش میدهد و هم کیفیت محصول نهایی را تضمین میکند.18
سه مرحله اصلی پردازش عبارتند از:
۲.۳.۱. افزودن کلاهک ‘۵ (5’ Capping)
تقریباً بلافاصله پس از شروع رونویسی، زمانی که طول رونوشت pre-mRNA به حدود ۲۰-۳۰ نوکلئوتید میرسد، یک نوکلئوتید گوانین تغییریافته به نام کلاهک ۷-متیلگوانوزین (7-methylguanosine cap) به انتهای ‘۵ آن اضافه میشود.20 این کلاهک چندین عملکرد حیاتی دارد:
- از انتهای ‘۵ mRNA در برابر تخریب توسط آنزیمهای نوکلئاز محافظت میکند.
- به عنوان یک سیگنال برای صادرات mRNA از هسته به سیتوپلاسم عمل میکند.
- نقش کلیدی در شناسایی mRNA توسط ریبوزوم برای آغاز فرآیند ترجمه دارد.24
۲.۳.۲. افزودن دم پلی-A در انتهای ‘۳ (3’ Polyadenylation)
پس از برش pre-mRNA در سیگنال پلیآدنیلاسیون (که در مرحله پایان رونویسی ذکر شد)، آنزیمی به نام پلی-A پلیمراز (Poly-A Polymerase) یک زنجیره بلند متشکل از ۵۰ تا ۲۵۰ نوکلئوتید آدنین را به انتهای ‘۳ تازه ایجاد شده اضافه میکند. این زنجیره به دم پلی-A (Poly-A tail) معروف است.6 وظایف این دم عبارتند از:
- افزایش پایداری مولکول mRNA در سیتوپلاสม، با کند کردن روند تخریب آن.
- کمک به فرآیند صادرات mRNA از هسته.
- ایفای نقش در آغاز ترجمه.24
۲.۳.۳. پیرایش RNA (RNA Splicing): حذف اینترونها و اتصال اگزونها
یکی از شگفتانگیزترین ویژگیهای ژنهای یوکاریوتی این است که توالی کدکننده آنها پیوسته نیست. این ژنها از دو نوع توالی تشکیل شدهاند: اگزونها (Exons) که حاوی اطلاعات کدکننده پروتئین هستند و اینترونها (Introns) که نواحی غیرکدکننده هستند و در میان اگزونها قرار گرفتهاند.21
برای اینکه یک پروتئین عملکردی ساخته شود، اینترونها باید از pre-mRNA حذف شده و اگزونها با دقت بسیار بالا به یکدیگر متصل شوند. این فرآیند که پیرایش یا اسپلایسینگ (Splicing) نام دارد، توسط یک ماشین مولکولی عظیم و پیچیده به نام اسپلایسوزوم (Spliceosome) انجام میشود.26 اسپلایسوزوم از پروتئینها و مولکولهای RNA کوچکی به نام RNAهای کوچک هستهای (snRNA) تشکیل شده است که با هم کمپلکسهای snRNP را میسازند.23 این کمپلکسها توالیهای مرزی خاصی را در ابتدا و انتهای هر اینترون شناسایی کرده و با دقت آن را به شکل یک حلقه (lariat) برش داده و خارج میکنند، سپس دو اگزون مجاور را به هم متصل میکنند.
پیرایش جایگزین (Alternative Splicing): پیچیدگی پیرایش در اینجا به پایان نمیرسد. یک pre-mRNA واحد میتواند به روشهای مختلفی پیرایش شود، به طوری که در هر حالت، ترکیب متفاوتی از اگزونها در mRNA بالغ نهایی باقی بماند. این پدیده که پیرایش جایگزین نام دارد، به یک ژن واحد اجازه میدهد تا چندین پروتئین مختلف (ایزوفرم) با عملکردهای متفاوت یا مشابه تولید کند. این مکانیسم، ظرفیت کدکنندگی ژنوم را به شدت افزایش میدهد و یکی از دلایل اصلی پیچیدگی موجودات یوکاریوتی است.21
بخش ۳: رمز ژنتیکی: زبان حیات
قبل از آنکه به پرده دوم نمایش، یعنی ترجمه، بپردازیم، لازم است با زبانی که در آن پیام ژنتیکی نوشته شده است، آشنا شویم. این زبان، که به آن رمز ژنتیکی (Genetic Code) میگویند، مجموعهای از قوانین است که سلولها برای تبدیل توالی نوکلئوتیدهای mRNA به توالی اسیدهای آمینه یک پروتئین از آن استفاده میکنند. این رمز، یک فرهنگ لغت مولکولی است که ارتباط بین دنیای اسیدهای نوکلئیک و دنیای پروتئینها را برقرار میکند.
۳.۱. کدونها: کلمات سهحرفی زیستشناسی
اطلاعات ژنتیکی در mRNA به صورت واحدهای سهنوکلئوتیدی ناهمپوشان به نام کدون (Codon) خوانده میشود.32 از آنجایی که چهار باز مختلف در RNA وجود دارد (آدنین (A)، اوراسیل (U)، گوانین (G) و سیتوزین (C))، تعداد کل کدونهای ممکن برابر با 43 یا ۶۴ حالت مختلف است.33
از این ۶۴ کدون:
- ۶۱ کدون برای ۲۰ اسید آمینه استاندارد کد میکنند.
- ۳ کدون به عنوان سیگنال توقف (Stop Codon) عمل کرده و به فرآیند ترجمه پایان میدهند.32
۳.۲. جدول استاندارد رمز ژنتیکی
جدول زیر، که به عنوان «سنگ روزتای» زیستشناسی مولکولی شناخته میشود، نگاشت کامل هر یک از ۶۴ کدون RNA را به اسید آمینه مربوطه یا سیگنال توقف نشان میدهد. این جدول، فرهنگ لغت جهانی برای سنتز پروتئین است.
| باز دوم | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| باز اول | U | C | A | G | باز سوم | ||||
| U | UUU | (Phe/F) فنیلآلانین | UCU | (Ser/S) سرین | UAU | (Tyr/Y) تیروزین | UGU | (Cys/C) سیستئین | U |
| UUC | (Phe/F) فنیلآلانین | UCC | (Ser/S) سرین | UAC | (Tyr/Y) تیروزین | UGC | (Cys/C) سیستئین | C | |
| UUA | (Leu/L) لوسین | UCA | (Ser/S) سرین | UAA | پایان | UGA | پایان | A | |
| UUG | (Leu/L) لوسین | UCG | (Ser/S) سرین | UAG | پایان | UGG | (Trp/W) تریپتوفان | G | |
| C | CUU | (Leu/L) لوسین | CCU | (Pro/P) پرولین | CAU | (His/H) هیستیدین | CGU | (Arg/R) آرژنین | U |
| CUC | (Leu/L) لوسین | CCC | (Pro/P) پرولین | CAC | (His/H) هیستیدین | CGC | (Arg/R) آرژنین | C | |
| CUA | (Leu/L) لوسین | CCA | (Pro/P) پرولین | CAA | (Gln/Q) گلوتامین | CGA | (Arg/R) آرژنین | A | |
| CUG | (Leu/L) لوسین | CCG | (Pro/P) پرولین | CAG | (Gln/Q) گلوتامین | CGG | (Arg/R) آرژنین | G | |
| A | AUU | (Ile/I) ایزولوسین | ACU | (Thr/T) ترئونین | AAU | (Asn/N) آسپاراژین | AGU | (Ser/S) سرین | U |
| AUC | (Ile/I) ایزولوسین | ACC | (Thr/T) ترئونین | AAC | (Asn/N) آسپاراژین | AGC | (Ser/S) سرین | C | |
| AUA | (Ile/I) ایزولوسین | ACA | (Thr/T) ترئونین | AAA | (Lys/K) لیزین | AGA | (Arg/R) آرژنین | A | |
| AUG | (Met/M) متیونین (آغاز) | ACG | (Thr/T) ترئونین | AAG | (Lys/K) لیزین | AGG | (Arg/R) آرژنین | G | |
| G | GUU | (Val/V) والین | GCU | (Ala/A) آلانین | GAU | (Asp/D) آسپارتیک اسید | GGU | (Gly/G) گلیسین | U |
| GUC | (Val/V) والین | GCC | (Ala/A) آلانین | GAC | (Asp/D) آسپارتیک اسید | GGC | (Gly/G) گلیسین | C | |
| GUA | (Val/V) والین | GCA | (Ala/A) آلانین | GAA | (Glu/E) گلوتامیک اسید | GGA | (Gly/G) گلیسین | A | |
| GUG | (Val/V) والین | GCG | (Ala/A) آلانین | GAG | (Glu/E) گلوتامیک اسید | GGG | (Gly/G) گلیسین | G | |
۳.۳. ویژگیهای کلیدی رمز
رمز ژنتیکی دارای چندین ویژگی برجسته است که آن را به یک سیستم اطلاعاتی کارآمد و مقاوم تبدیل کرده است.
- جهانشمولی (Universality): این رمز تقریباً در تمام موجودات زنده روی زمین، از باکتری تا انسان، یکسان است. به عبارت دیگر، کدون CCU در یک باکتری، یک گیاه و یک انسان، همگی اسید آمینه پرولین را کد میکند. این جهانشمولی، یکی از قویترین شواهد برای وجود یک نیای مشترک برای تمام حیات است. (البته استثناهای جزئی در میتوکندریها و برخی آغازیان مشاهده شده است 36). این زبان مشترک، سنگ بنای مهندسی ژنتیک مدرن است. به دلیل اینکه یک سلول باکتری رمز ژنتیکی را همانند یک سلول انسانی میخواند، میتوان یک ژن انسانی (مانند ژن انسولین) را به یک باکتری منتقل کرد و آن باکتری، پروتئین انسانی را تولید خواهد کرد. این قابلیت انتقال اطلاعات بین گونهها، انقلابی در پزشکی و بیوتکنولوژی ایجاد کرده است.
- چندرمزی یا افزونگی (Degeneracy/Redundancy): رمز ژنتیکی «چندرمز» است، به این معنی که بیشتر اسیدهای آمینه توسط بیش از یک کدون کد میشوند.32 به عنوان مثال، اسید آمینه لوسین توسط شش کدون مختلف (UUA، UUG، CUU، CUC، CUA، CUG) مشخص میشود.
- جایگاه لرزان (Wobble Position): این چندرمزی اغلب در سومین باز کدون مشاهده میشود. این انعطافپذیری در جفت شدن باز سوم کدون با باز متناظر در tRNA (که در بخش بعد توضیح داده خواهد شد)، به «فرضیه لرزش» (Wobble Hypothesis) معروف است. این ویژگی به سلول اجازه میدهد تا با تعداد کمتری tRNA، تمام ۶۱ کدون را رمزگشایی کند.34 ساختار رمز ژنتیکی به گونهای بهینه شده است که اثرات جهشها را به حداقل برساند. چندرمزی در جایگاه سوم باعث میشود بسیاری از جهشهای نقطهای «خاموش» (Silent) باشند، یعنی با وجود تغییر در DNA، اسید آمینه نهایی تغییر نکند. علاوه بر این، آرایش کدونها تصادفی نیست. کدونهای مربوط به اسیدهای آمینه با خواص بیوشیمیایی مشابه (مثلاً آبگریز یا آبدوست) در جدول در کنار هم قرار گرفتهاند. این بدان معناست که یک جهش «دگرمعنا» (Missense) که اسید آمینه را تغییر میدهد، به احتمال زیاد آن را با یک اسید آمینه مشابه از نظر شیمیایی جایگزین میکند، که این امر شانس عملکردی باقی ماندن پروتئین را افزایش میدهد. این ساختار، نشاندهنده یک سیستم مقاوم در برابر خطا است که توسط فرگشت بهینه شده است.
- سیگنالهای آغاز و پایان: رمز ژنتیکی دارای «علائم نگارشی» است. کدون AUG معمولاً به عنوان کدون آغاز (Start Codon) عمل میکند. این کدون نه تنها اسید آمینه متیونین را کد میکند، بلکه «چارچوب خوانش» (Reading Frame) صحیح را برای ریبوزوم تعیین میکند.37 سه کدون UAA، UAG و UGA نیز به عنوان کدونهای پایان (Stop Codons) عمل میکنند و هیچ اسید آمینهای را کد نمیکنند، بلکه سیگنال خاتمه سنتز پروتئین را صادر میکنند.32
بخش ۴: ترجمه: ساختن پروتئین
ترجمه، اوج فرآیند بیان ژن است؛ مرحلهای که در آن زبان نوکلئوتیدی mRNA به زبان اسید آمینهای پروتئینها برگردانده میشود. این فرآیند پیچیده و پرانرژی در کارخانههای مولکولی سلول به نام ریبوزومها رخ میدهد و نیازمند هماهنگی دقیق بین چندین بازیگر کلیدی است. نتیجه نهایی، یک زنجیره پلیپپتیدی است که پس از تاخوردگی صحیح، به یک پروتئین عملکردی تبدیل میشود.
۴.۱. ماشینآلات ترجمه: بازیگران کلیدی
برای اجرای موفقیتآمیز ترجمه، سه نوع مولکول اصلی باید با یکدیگر همکاری کنند:
- RNA پیامرسان (mRNA): این مولکول، الگوی عمل است. mRNA بالغ و پردازششده، توالی کدونهایی را که باید خوانده شوند، از هسته به سیتوپلاسم حمل میکند.38
- ریبوزومها (Ribosomes): این ساختارهای عظیم، ماشینهای پروتئینسازی سلول هستند. هر ریبوزوم از دو زیرواحد (یک زیرواحد بزرگ و یک زیرواحد کوچک) تشکیل شده است که هر دو از RNA ریبوزومی (rRNA) و پروتئین ساخته شدهاند. ریبوزوم در طول mRNA حرکت میکند، کدونهای آن را میخواند و تشکیل پیوندهای پپتیدی بین اسیدهای آمینه را کاتالیز میکند. ریبوزوم دارای سه جایگاه کلیدی برای اتصال tRNA است 39:
- جایگاه A (آمینوآسیل): محل ورود tRNA حامل اسید آمینه جدید.
- جایگاه P (پپتیدیل): محل نگهداری tRNA متصل به زنجیره پلیپپتیدی در حال رشد.
- جایگاه E (خروج): محل خروج tRNA خالی (بدون اسید آمینه) از ریبوزوم.
- RNA ناقل (tRNA): این مولکولهای RNA کوچک و L-شکل، به عنوان مولکولهای آداپتور یا مترجم عمل میکنند. هر مولکول tRNA دو ناحیه عملکردی حیاتی دارد: یک حلقه آنتیکدون (Anticodon) که مکمل یک کدون خاص در mRNA است، و یک انتهای ‘۳ که اسید آمینه متناظر با آن کدون به آن متصل میشود. وظیفه tRNAها این است که اسید آمینه صحیح را بر اساس دستور mRNA به ریبوزوم بیاورند.38 فرآیند اتصال یک اسید آمینه به tRNA مربوطهاش، «شارژ شدن» نامیده میشود و توسط آنزیمهای بسیار دقیقی به نام آمینوآسیل-tRNA سنتتازها و با مصرف انرژی ATP انجام میشود.42
۴.۲. فرآیند ترجمه: مونتاژ زنجیره پلیپپتیدی
همانند رونویسی، ترجمه نیز در سه مرحله اصلی انجام میشود: آغاز، طویل شدن و پایان.
۴.۲.۱. آغاز (Initiation): مونتاژ ریبوزوم روی پیام
این مرحله، تمام اجزای لازم برای شروع سنتز پروتئین را در جایگاه صحیح گرد هم میآورد.
- اتصال زیرواحد کوچک: زیرواحد کوچک ریبوزوم به انتهای ‘۵ مولکول mRNA متصل میشود. در یوکاریوتها، این اتصال با شناسایی کلاهک ‘۵ تسهیل میشود. سپس زیرواحد کوچک در طول mRNA حرکت میکند (اسکن میکند) تا به اولین کدون آغاز (AUG) برسد.12
- اتصال tRNA آغازگر: یک tRNA ویژه به نام tRNA آغازگر که حامل اسید آمینه متیونین (Met) است، کدون آغاز AUG را از طریق جفت شدن بازهای مکمل بین کدون و آنتیکدون خود شناسایی کرده و به آن متصل میشود.41
- اتصال زیرواحد بزرگ: در نهایت، زیرواحد بزرگ ریبوزوم به این مجموعه میپیوندد و کمپلکس آغاز ترجمه را کامل میکند. این اتصال به گونهای است که tRNA آغازگر در جایگاه P ریبوزوم قرار میگیرد. در این لحظه، جایگاه A خالی و آماده پذیرش tRNA بعدی است. این فرآیند نیازمند انرژی حاصل از هیدرولیز GTP و کمک پروتئینهایی به نام فاکتورهای آغازگر (IFها در پروکاریوتها و eIFها در یوکاریوتها) است.39
۴.۲.۲. طویل شدن (Elongation): چرخه افزودن اسیدهای آمینه
این مرحله، قلب فرآیند ترجمه است و به صورت یک چرخه سهمرحلهای برای هر اسید آمینه جدید تکرار میشود.40
- شناسایی کدون: یک tRNA شارژ شده که آنتیکدون آن مکمل کدون موجود در جایگاه A ریبوزوم است، وارد این جایگاه میشود. این فرآیند با کمک فاکتورهای طویلسازی (EF-Tu در پروکاریوتها، eEF1A در یوکاریوتها) و مصرف انرژی از هیدرولیز GTP انجام میشود.39 در این مرحله، فرآیند بازخوانی جنبشی (kinetic proofreading) برای اطمینان از صحت جفتشدن کدون-آنتیکدون رخ میدهد. جفتشدن صحیح، یک تغییر ساختاری در ریبوزوم ایجاد میکند که هیدرولیز GTP را تسریع کرده و tRNA را در جایگاه A قفل میکند. جفتشدن نادرست، پایداری کمتری دارد و tRNA قبل از این قفل شدن، از ریبوزوم جدا میشود. این مکانیسم، دقت فوقالعاده بالای ترجمه را تضمین میکند.
- تشکیل پیوند پپتیدی: rRNA موجود در زیرواحد بزرگ ریبوزوم (که به عنوان یک آنزیم RNA یا رایبوزیم عمل میکند)، تشکیل یک پیوند پپتیدی بین اسید آمینه جدید در جایگاه A و انتهای زنجیره پلیپپتیدی متصل به tRNA در جایگاه P را کاتالیز میکند. در نتیجه، کل زنجیره پلیپپتیدی در حال رشد به tRNA موجود در جایگاه A منتقل میشود.39
- جابهجایی (Translocation): ریبوزوم به اندازه یک کدون در طول mRNA به سمت انتهای ‘۳ حرکت میکند. این حرکت که نیازمند فاکتور طویلسازی دیگری (EF-G در پروکاریوتها، eEF2 در یوکاریوتها) و هیدرولیز GTP است، باعث جابهجایی tRNAها میشود: tRNA خالی از جایگاه P به جایگاه E منتقل شده و از آنجا خارج میشود؛ tRNA حامل زنجیره پلیپپتیدی از جایگاه A به جایگاه P منتقل میشود. اکنون جایگاه A دوباره خالی است و برای ورود tRNA بعدی آماده است.40
۴.۲.۳. پایان (Termination): آزاد کردن پروتئین نهایی
چرخه طویل شدن تا زمانی ادامه مییابد که یکی از سه کدون پایان (UAA، UAG یا UGA) وارد جایگاه A ریبوزوم شود.41
- هیچ tRNAای با آنتیکدون مکمل برای کدونهای پایان وجود ندارد. در عوض، پروتئینهایی به نام فاکتورهای آزادکننده (Release Factors) این کدونها را شناسایی کرده و به جایگاه A متصل میشوند.40
- اتصال فاکتور آزادکننده باعث میشود که آنزیم پپتیدیل ترانسفراز ریبوزوم، یک مولکول آب را به زنجیره پلیپپتیدی اضافه کند. این واکنش، زنجیره را از tRNA موجود در جایگاه P جدا کرده و پروتئین تازه سنتز شده آزاد میشود.
- در نهایت، کل مجموعه شامل زیرواحدهای ریبوزوم، mRNA و tRNA از یکدیگر جدا میشوند و برای یک دور جدید از ترجمه آماده میشوند.39
هزینه بالای انرژی در فرآیند ترجمه، منطق قدرتمندی برای وجود mRNA به عنوان یک واسطه را فراهم میکند. به جای ترجمه مستقیم از روی الگوی گرانبهای DNA، سلول نسخههای یکبار مصرف mRNA را تولید میکند. اگر از یک الگوی DNA به طور مکرر استفاده میشد، هرگونه آسیب به آن فاجعهبار بود. با استفاده از واسطههای موقتی mRNA، سلول میتواند خروجی یک ژن واحد را به شدت تقویت کند (یک ژن میتواند صدها mRNA تولید کند که هر کدام بارها ترجمه میشوند) و همزمان از طرح اولیه DNA محافظت نماید. این هزینه بالای انرژی با تقویت عظیم سیگنال و حفاظت از ژنوم توجیه میشود.
بخش ۵: داستان دو نوع سلول: مقایسه بیان ژن در پروکاریوتها و یوکاریوتها
اگرچه اصول بنیادین Central Dogma در تمام حیات مشترک است، اما استراتژیها و مکانیسمهای اجرای آن در دو حوزه بزرگ حیات، یعنی پروکاریوتها (موجودات بدون هسته مشخص، مانند باکتریها) و یوکاریوتها (موجودات دارای هسته، مانند گیاهان، حیوانات و قارچها)، تفاوتهای چشمگیری دارند. این تفاوتها عمدتاً از معماری متفاوت سلولی آنها نشأت میگیرد و بازتابی از استراتژیهای فرگشتی متمایز آنهاست.
۵.۱. مکان و جفتشدگی: پیامدهای وجود هسته
مهمترین تفاوت در سازماندهی مکانی و زمانی این فرآیندها نهفته است:
- پروکاریوتها: در این سلولها، به دلیل عدم وجود غشای هسته، DNA در ناحیهای از سیتوپلاسم به نام «نوکلئوئید» قرار دارد. این امر به رونویسی و ترجمه اجازه میدهد تا به صورت جفتشده (Coupled) رخ دهند. یعنی، به محض اینکه بخشی از مولکول mRNA رونویسی میشود، ریبوزومها میتوانند به آن متصل شده و ترجمه را آغاز کنند، حتی در حالی که RNA پلیمراز هنوز در حال رونویسی بقیه ژن است.12 این جفتشدگی، امکان پاسخ بسیار سریع به تغییرات محیطی را فراهم میکند.
- یوکاریوتها: در این سلولها، وجود یک هسته با غشای مشخص، این دو فرآیند را از یکدیگر جدا میکند. رونویسی در داخل هسته انجام میشود و ترجمه در سیتوپلاسم. این جدایی مکانی و زمانی، نیازمند فرآیندهای پیچیده پردازش و صادرات mRNA است که در بخش ۲ به آنها پرداخته شد و لایههای تنظیمی بیشتری را برای کنترل بیان ژن فراهم میکند.45
۵.۲. تفاوت در ماشینآلات رونویسی و ترجمه
ماشینآلات مولکولی در این دو نوع سلول نیز تفاوتهای ساختاری و عملکردی دارند:
- RNA پلیمراز: پروکاریوتها تنها یک نوع RNA پلیمراز برای تمام رونویسیها دارند، در حالی که یوکاریوتها از سه نوع تخصصی (I، II و III) بهره میبرند.12
- ریبوزومها: ریبوزومهای پروکاریوتی کوچکتر (با ضریب تهنشینی 70S) و از زیرواحدهای 30S و 50S تشکیل شدهاند. ریبوزومهای یوکاریوتی بزرگتر (80S) و متشکل از زیرواحدهای 40S و 60S هستند.12 این تفاوت در اندازه و ساختار، یک هدف کلیدی برای بسیاری از آنتیبیوتیکها است. این داروها به طور انتخابی به ریبوزومهای 70S باکتریایی متصل شده و سنتز پروتئین را در آنها مهار میکنند، در حالی که بر ریبوزومهای 80S سلولهای میزبان تأثیری ندارند.
- فاکتورهای آغازگر: فرآیند آغاز ترجمه در یوکاریوتها بسیار پیچیدهتر است و به تعداد بیشتری فاکتور آغازگر (eIFs) نسبت به پروکاریوتها (IFs) نیاز دارد.40
۵.۳. ساختار و تنظیم mRNA: سرعت در برابر پیچیدگی
استراتژیهای مربوط به خود مولکول mRNA نیز کاملاً متفاوت است:
- پردازش mRNA: mRNA پروکاریوتی معمولاً بدون هیچگونه تغییری مستقیماً ترجمه میشود. در مقابل، pre-mRNA یوکاریوتی تحت پردازشهای گستردهای شامل افزودن کلاهک ‘۵، دم پلی-A و پیرایش قرار میگیرد.12
- ساختار mRNA: mRNA پروکاریوتی اغلب پلیسیسترونی (Polycistronic) است، به این معنی که یک مولکول mRNA واحد میتواند چندین پروتئین مختلف را کد کند (معمولاً پروتئینهایی که در یک مسیر متابولیکی مشترک نقش دارند و در ساختاری به نام «اپرون» سازماندهی شدهاند).12 mRNA یوکاریوتی تقریباً همیشه مونوسیسترونی (Monocistronic) است و تنها یک پروتئین را کد میکند.12
- پایداری mRNA: mRNA پروکاریوتی بسیار ناپایدار است و طول عمری در حد چند ثانیه تا چند دقیقه دارد که متناسب با نیاز آنها به سازگاری سریع است. mRNA یوکاریوتی بسیار پایدارتر است و میتواند برای ساعتها یا حتی روزها باقی بماند که امکان تولید طولانیمدت پروتئین را فراهم میکند.52
- آغاز ترجمه: ریبوزومهای پروکاریوتی یک توالی خاص به نام توالی شاین-دالگارنو (Shine-Dalgarno sequence) را در بالادست کدون آغاز شناسایی کرده و به آن متصل میشوند.12 ریبوزومهای یوکاریوتی معمولاً به کلاهک ‘۵ متصل شده و سپس در طول mRNA حرکت میکنند تا به اولین کدون آغاز AUG برسند.12
این تفاوتها تصادفی نیستند، بلکه بازتابی از استراتژیهای فرگشتی متمایز این دو گروه از موجودات هستند. سیستم پروکاریوتی برای سرعت و کارایی متابولیکی بهینه شده است. جفتشدگی رونویسی-ترجمه، mRNAهای پلیسیسترونی و ناپایدار به باکتریها اجازه میدهد تا به سرعت پروفایل پروتئینی خود را با محیط در حال تغییر تطبیق دهند. در مقابل، سیستم یوکاریوتی برای دقت تنظیمی و پیچیدگی بهینه شده است. جداسازی فرآیندها، پردازش گسترده mRNA، پیرایش جایگزین و پیامهای مونوسیسترونی، امکان بیان ژن افتراقی و تنظیمشدهای را فراهم میکند که برای ساخت و نگهداری یک موجود پرسلولی پیچیده با انواع سلولهای تخصصی ضروری است.
جدول: خلاصهای از تفاوتهای کلیدی بیان ژن
| ویژگی | پروکاریوتها | یوکاریوتها |
|---|---|---|
| محل رونویسی | سیتوپلاسم | هسته |
| محل ترجمه | سیتوپلاسم | سیتوپلاسم |
| جفتشدگی رونویسی-ترجمه | بله، همزمان هستند | خیر، از نظر مکانی و زمانی جدا هستند |
| RNA پلیمراز | یک نوع | سه نوع (I, II, III) |
| پردازش mRNA | به ندرت (معمولاً بدون پردازش) | گسترده (کلاهک ‘۵، دم پلی-A، پیرایش) |
| اینترونها | بسیار نادر | رایج |
| ساختار mRNA | معمولاً پلیسیسترونی | تقریباً همیشه مونوسیسترونی |
| ریبوزومها | 70S (30S + 50S) | 80S (40S + 60S) |
| آغاز ترجمه | توالی شاین-دالگارنو | اسکن از کلاهک ‘۵ برای یافتن AUG |
| پایداری mRNA | ناپایدار (چند دقیقه) | پایدار (چند ساعت تا چند روز) |
بخش ۶: نتیجهگیری: سمفونی بیان ژن
سفر از DNA به پروتئین، یک مسیر خطی و ساده نیست، بلکه یک سمفونی پیچیده و هماهنگ از برهمکنشهای مولکولی است که در هر لحظه در تریلیونها سلول بدن ما در حال اجراست. این فرآیند، که توسط Central Dogma زیستشناسی مولکولی چارچوببندی شده است، در دو پرده اصلی به اوج خود میرسد: رونویسی، که در آن پیام ژنتیکی از آرشیو پایدار DNA به یک رونوشت موقتی و قابل حمل RNA کپی میشود؛ و ترجمه، که در آن این پیام توسط ماشینآلات سلولی رمزگشایی شده و به پروتئینهای عملکردی، یعنی بازیگران اصلی صحنه حیات، تبدیل میشود.
ما دیدیم که چگونه در یوکاریوتها، این فرآیند با لایههای اضافی از پیچیدگی و تنظیم، از جمله پردازش دقیق mRNA و پیرایش جایگزین، غنیتر شده است؛ مکانیسمهایی که به موجودات پیچیده اجازه میدهند تا از ژنوم خود، تنوع پروتئینی شگفتانگیزی را استخراج کنند. همچنین، مقایسه این فرآیندها بین پروکاریوتها و یوکاریوتها نشان داد که چگونه فرگشت، دو استراتژی متفاوت را برای مدیریت جریان اطلاعات ژنتیکی شکل داده است: یکی مبتنی بر سرعت و سازگاری، و دیگری مبتنی بر کنترل و پیچیدگی.
در نهایت، درک این مسیر بنیادین، از توالی بازها در یک مارپیچ دوگانه تا ساختار سهبعدی یک پروتئین تاخورده، نه تنها یکی از بزرگترین دستاوردهای فکری بشر در قرن بیستم است، بلکه کلید درک سلامت و بیماری، اساس بیوتکنولوژی مدرن و پنجرهای به سوی عمیقترین اسرار خود حیات است. این سمفونی مولکولی، با تمام ظرافت، دقت و پویایی خود، همچنان به نواختن ادامه میدهد و موسیقی متن هر سلول زنده را میسازد.
تایید شده توسط متخصص
درباره نویسنده و بازبین علمی
آگاهی، کلید درک سلامت
درک فرآیندهای بنیادین رونویسی و ترجمه، سنگ بنای فهم عمیقتر از سلامت، بیماریهای ژنتیکی و پزشکی مدرن است. این دانش، شما را برای تصمیمگیریهای آگاهانه در مسیر سلامتتان توانمند میسازد.
دریافت مشاوره ژنتیک